Trong lĩnh vực lập trình web, thuật ngữ Crawler Data đã không còn xa lạ. Tuy nhiên, để làm việc được với nó đòi hỏi bạn cần có kiến thức về lập trình.
Vậy Crawler Data là gì? Làm sao để Crawler Data trong WordPress? Bài viết này tôi sẽ chia sẻ chi tiết về vấn đề này.

Crawler Data là gì?
Crawler Data chính là thu thập dữ liệu từ một trang web bất kì, hoặc chỉ định trước rồi phân tích cú pháp mã nguồn HTML để đọc dữ liệu và bóc tách thông tin dữ liệu theo yêu cầu mà người dùng đặt ra.
Crawler Data bằng những cách nào?
Bạn có thể sử dụng bất kỳ ngôn ngữ lập trình nào để Crawler Data. Mỗi ngôn ngữ sẽ có ưu điểm và nhược điểm riêng. Bài viết này tôi đề cập đến WordPress nên tôi sẽ sử dụng PHP để thực hiện công việc Crawler.
Với ngôn ngữ lập trình PHP, có những cách sau:
- Sử dụng thư viện Simple HTML Dom
- Sử dụng CURL kết hợp với Regular Expression để bóc tách
- Kết hợp CURL và Simple HTML Dom (Trong trường hợp Simple HTML Dom không lấy được nội dung hoặc Nội dung được Render bằng Ajax)
Việc bóc tách bằng Regular Expression (Biểu thức chính quy) khá phức tạp cho bạn nào chưa có kinh nghiệm viết biểu thức chính quy.
Crawler Data có cần sử dụng phần mềm không?
Nếu nội dung được Render bằng Ajax thì bạn phải tìm được Request Ajax (Sử dụng tab Network của Chrome), sau đó test Request đó bằng phần mềm Postman để xem Request đó có trả về nội dung cần lấy không?
Vậy bạn cần chuẩn bị phần mềm Postman để thực hiện công việc này: https://www.postman.com
Hướng dẫn sử dụng SIMPLE HTML DOM
Simple HTML Dom là một thư viện chuyên được sử dụng để bóc tách dữ liệu. Trang chủ thư viện: https://simplehtmldom.sourceforge.io
Các bước thực hiện:
Bước 01: Tải thư viện Simple HTML Dom và require vào dự án cần làm
Download thư viện tại đây: https://sourceforge.net/projects/simplehtmldom
Giải nén và require file simple_html_dom.php vào project cần làm thông qua hàm require_once
<?php require_once 'simple_html_dom.php';
Bước 02: Xác định website cần lấy dữ liệu
Bạn cần xác định website cần lấy dữ liệu, sau đó xác định thành phần cần lấy trên website đó. Hãy trả lời các câu hỏi sau:
- Bạn cần lấy một nội dung hay nhiều nội dung? (Nếu một nội dung thì copy cho nhanh)
- Bạn cần lấy nhiều nội dung trong một chuyên mục hay nhiều chuyên mục?
- Trong trường hợp chuyên mục có phân trang, bạn muốn lấy tất cả các trang hay chỉ lấy trang đầu tiên?
- Bạn cần xử lý dữ liệu sau khi lấy về không? (Xoá ảnh, xoá liên kết, xoá thành phần không thiết)
Bước 03: Viết code bóc tách dữ liệu
Trước tiên, bạn hãy dùng ham file_get_html() để đọc nội dung trang cần lấy.
Giả sử tôi cần lấy tiêu đề, nội dung, link ảnh các bài viết trong chuyên mục WordPress trên website hoangan.net. Tôi sẽ viết như sau:
$html_content = file_get_html('https://hoangan.net/wordpress');
Tiếp theo, bạn thử echo biến $html_content xem có hiện nội dung chuyên mục của web gốc ra không? Nếu có hiện là bạn đã thành công bước đầu.
Tiếp theo, bạn cần phân tích thành phần HTML cần lấy. Trong trường hợp này tôi cần lấy ra link của tất cả bài viết chuyên mục, sau đó tôi sẽ đọc từng bài và lấy ra tiêu đề, nội dung. Còn ảnh đại diện tôi sẽ lấy ở trang chuyên mục (Vì trong trang chi tiết không có ảnh đại diện)
Như vậy, tôi cần phải tìm được thành phần HTML lặp trong trang chuyên mục.
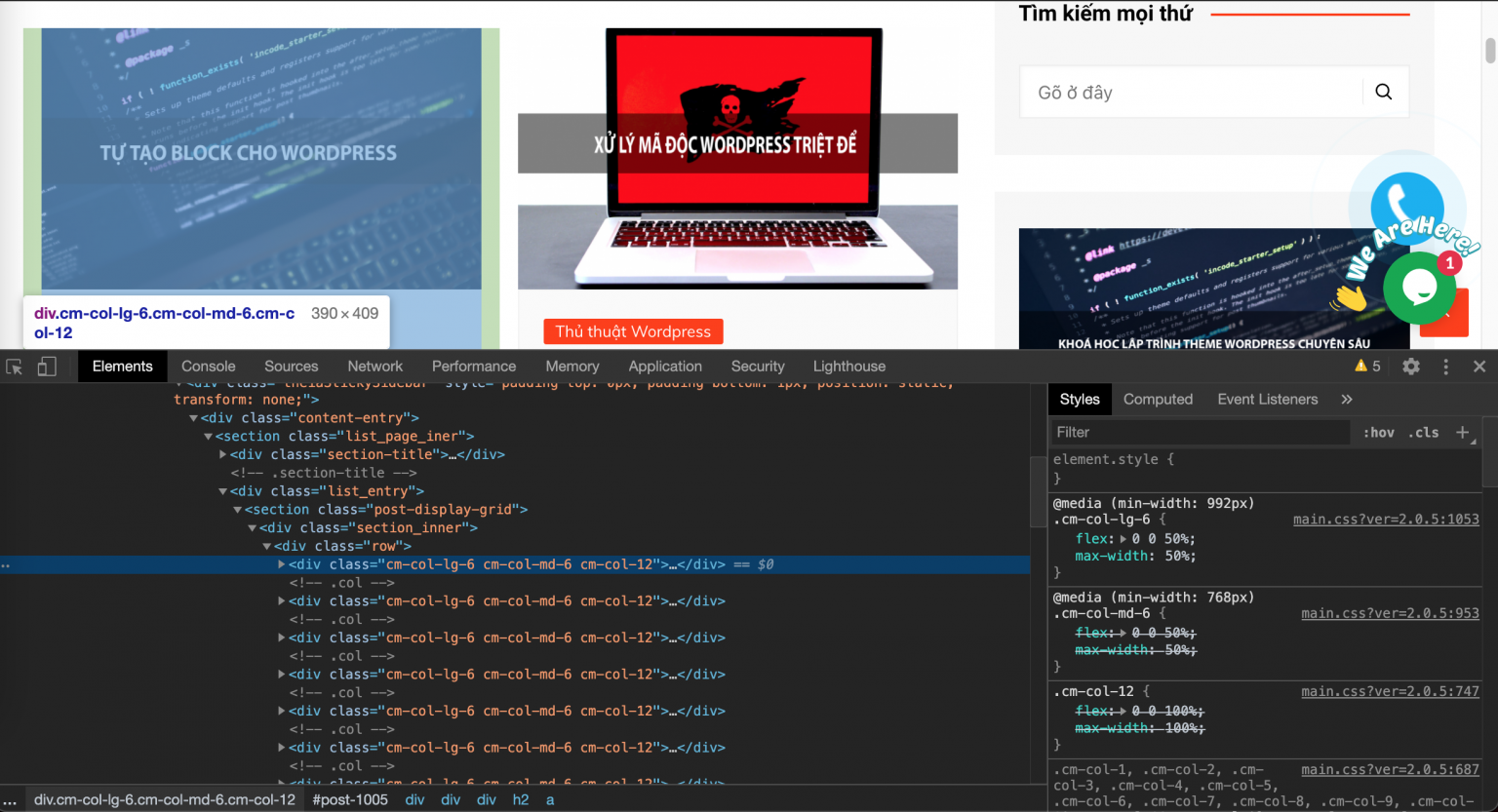
Nhìn vào hình bạn sẽ thấy thẻ <div class="cm-col-lg-6 cm-col-md-6 cm-col-12"> đang lặp bao quanh từng bài viết.
Như vậy ta sẽ viết code như sau:
$list_post = $html_content->find('.list_entry .cm-col-lg-6');
Bạn sẽ thấy nó giống như Selector trong CSS. Tôi phải đưa .list_entry vào vì có thể trong trang sẽ có nhiều chỗ dùng .cm-col-lg-6
Bây giờ, bạn sử dụng vòng lặp để đọc từng bài viết, sau đó ta lại bóc tách từng bài.
if (!empty($list_post)){
foreach ($list_post as $post){
//Bóc tách từng post
}
}
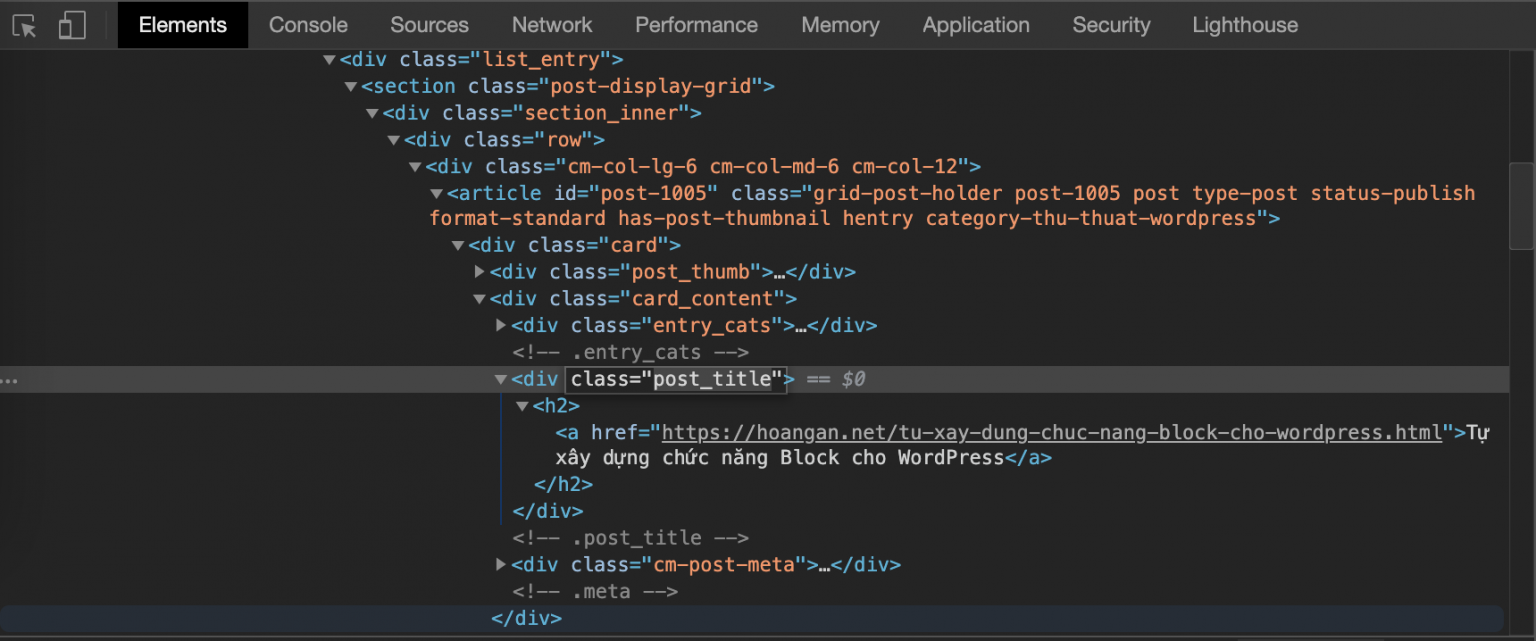
Phân tích từng bài viết, bạn sẽ thấy link từng bài viết sẽ nằm trong cặp thẻ h2. Việc bây giờ tôi sẽ phải lấy nội dung của thuộc tính href
Code như sau:
if (!empty($list_post)){
foreach ($list_post as $post){
$post_link = $post->find('.post_title h2 a', 0)->href;
}
}
Bạn thấy phương thức find có 2 tham số:
- Tham số đầu tiên: Selector (Giống như CSS)
- Tham số thứ hai: Index (Số thứ tự cần lấy, bắt đầu từ 0). Kể cả chỉ có 1 HTML bạn cũng phải truyền index = 0
Các thuộc tính của phương thức find():
- Các thuộc tính của thẻ HTML (Ví dụ: href, src, id, class)
plaintext: Lấy nội dung của một thẻ HTML (Chỉ lấy text)innertext: Lấy nội dung của một thẻ HTML (Lấy cả HTML)outertext: Lấy cả nội dung và thẻ đang Selector
Tiếp theo, tôi sẽ lấy link ảnh đại diện
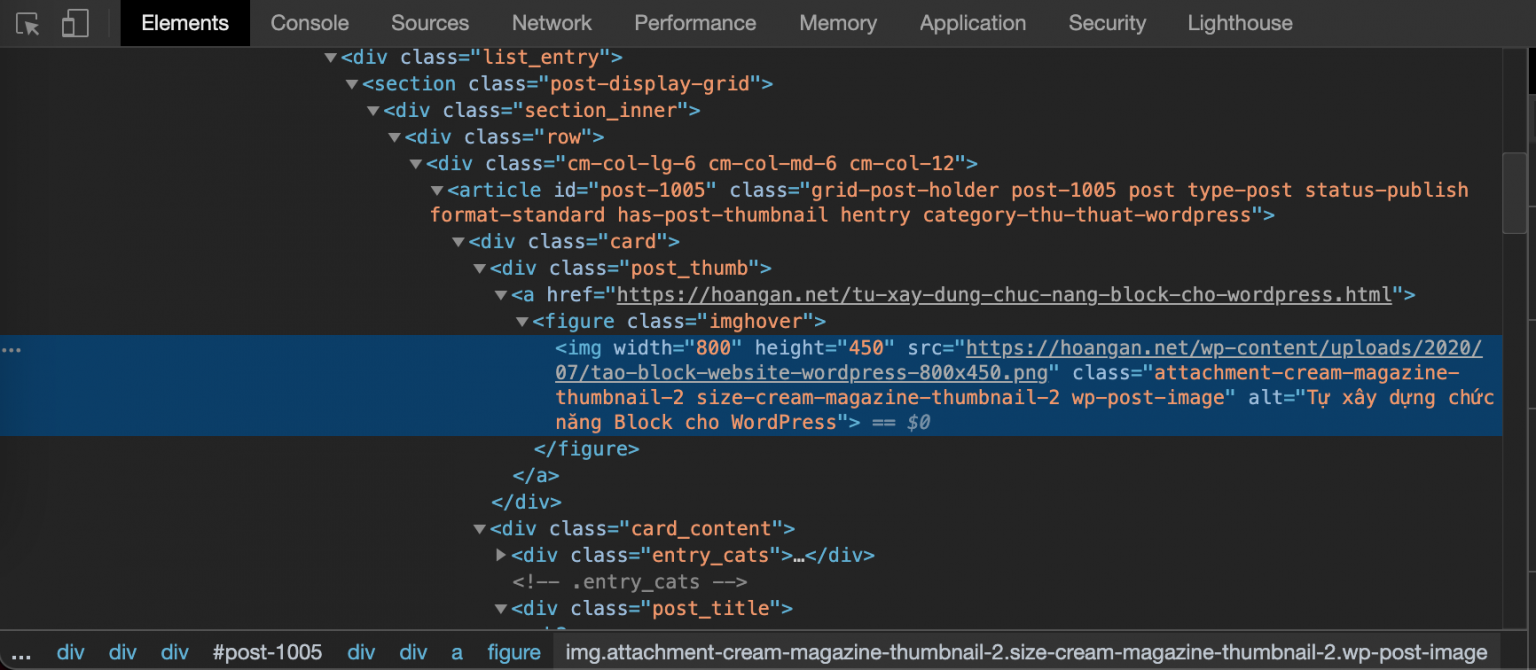
Đến đây, bạn đã biết cách lấy rồi đúng không? Tham khảo code của tôi nhé
if (!empty($list_post)){
foreach ($list_post as $post){
$post_link = $post->find('.post_title h2 a', 0)->href;
$thumb = $post->find('.post_thumb img')->src;
}
}
Tiếp theo, tôi sẽ lấy tiêu đề, nội dung trong trang chi tiết bài viết. Code như sau:
if (!empty($list_post)){
foreach ($list_post as $post){
$post_link = $post->find('.post_title h2 a', 0)->href;
$thumb = $post->find('.post_thumb img')->src;
//Post Detail
$html_detail = file_get_html($post_link);
$title = $html_detail->find('.content-entry .the_title h1', 0)->plaintext;
$content = $html_detail->find('.content-entry .the_content', 0)->innertext;
}
}
Như vậy tôi đã lấy được đủ thông tin rồi. Nếu bạn muốn xử lý dữ liệu hãy dùng biểu thức chính quy để xử lý.
Giờ làm gì với dữ liệu này là việc của bạn.
Crawler Data trong WordPress như thế nào?
Bạn đã Crawler Data được bằng Simple HTML Dom, thì bạn chỉ cần đưa vào WordPress là được. Sau đây, tôi sẽ hướng dẫn bạn áp dụng với WordPress.
Đầu tiên, bạn hãy sao chép file simple_html_dom.php vào thư mục theme bạn đang sử dụng.
Mở file functions.php và chèn đoạn code sau vào đầu file (Sau <?php)
require_once 'simple_html_dom.php';
Tiếp theo, tôi sẽ sử dụng hook init kết hợp với biến $_GET để tạo link thực hiện crawler. Khi tôi load link đó sẽ thực viện crawler và chèn nội dung vào bài viết WordPress.
function add_crawl_data(){
if (!is_admin() && isset($_GET['act']) && $_GET['act']=='crawl'){
//Code Crawler
die();
}
}
add_action('init', 'add_crawl_data');
Như vậy, link chạy crawler sẽ có dạng như sau: http://tenmiencuaban/?act=crawl
Tiếp theo, tôi đưa code crawler vào:
function add_crawl_data(){
if (!is_admin() && isset($_GET['act']) && $_GET['act']=='crawl'){
//Code Crawler
$html_content = file_get_html('https://hoangan.net/wordpress');
if (!empty($list_post)){
foreach ($list_post as $post){
$post_link = $post->find('.post_title h2 a', 0)->href;
$thumb = $post->find('.post_thumb img')->src;
//Post Detail
$html_detail = file_get_html($post_link);
$title = $html_detail->find('.content-entry .the_title h1', 0)->plaintext;
$content = $html_detail->find('.content-entry .the_content', 0)->innertext;
}
}
die();
}
}
add_action('init', 'add_crawl_data');
Sau khi lấy được dữ liệu rồi, tôi tiến hành việc insert vào WordPress. Trước khi insert, tôi cần phải kiểm tra xem bài viết đó có tồn tại trong website chưa?
Sử dụng hàm post_exists bạn nhé. Nhưng để hàm này hoạt động, bạn cần chèn đoạn code sau trước khi gọi nó:
if ( ! function_exists( 'post_exists' ) ) {
require_once( ABSPATH . 'wp-admin/includes/post.php' );
}
Tiếp theo, tôi sử dụng hàm wp_insert_post để chèn vào WordPress
$args = array( 'post_type' => 'post', 'post_status' => 'publish', 'post_title' => $title, 'post_content' => $content ); $post_id = wp_insert_post($args);
Nếu biến $post_id trả về số nguyên dương thì vài viết đã insert thành công.
Tiếp theo, tôi sẽ thực hiện việc set chuyên mục cho bài viết vừa insert. Tôi sẽ sử dụng hàm wp_set_post_terms
if ($post_id>0){
wp_set_post_terms($post_id, 41, 'category');
}
Trong đó có 3 tham số:
- Tham số đầu tiên: Post ID
- Tham số thứ hai: ID của chuyên mục
- Tham số thứ ba: Slug của Taxonomy (Chuyên mục trong WordPress có slug là: category)
Tiếp theo, tôi cần set ảnh đại diện cho bài viết. Tuy nhiên, WordPress không cho phép sử dụng link ảnh ngoài để set ảnh đại diện. Tôi sẽ phải tải ảnh về thư viện của WordPress.
Trước đây tôi có một bài hướng dẫn làm việc này. Mời bạn đọc qua bài viết Lấy Link Ảnh Ngoài Làm Thumbnail Cho WordPress
Trong bài đó, tôi đã chia sẻ sẵn một hàm. Bạn copy nội dung hàm đó bỏ vào file functions.php
function Generate_Featured_Image( $image_url, $post_id ){
$upload_dir = wp_upload_dir();
$image_data = file_get_contents($image_url);
$filename = basename($image_url);
if(wp_mkdir_p($upload_dir['path'])) $file = $upload_dir['path'] . '/' . $filename;
else $file = $upload_dir['basedir'] . '/' . $filename;
file_put_contents($file, $image_data);
$wp_filetype = wp_check_filetype($filename, null );
$attachment = array(
'post_mime_type' => $wp_filetype['type'],
'post_title' => sanitize_file_name($filename),
'post_content' => '',
'post_status' => 'inherit'
);
$attach_id = wp_insert_attachment( $attachment, $file, $post_id );
require_once(ABSPATH . 'wp-admin/includes/image.php');
$attach_data = wp_generate_attachment_metadata( $attach_id, $file );
$res1= wp_update_attachment_metadata( $attach_id, $attach_data );
$res2= set_post_thumbnail( $post_id, $attach_id );
}
Tiếp theo, bạn thực hiện set thumbnail như sau:
if ($post_id>0){
wp_set_post_terms($post_id, 41, 'category');
Generate_Featured_Image($thumb, $post_id);
}
Có vẻ ok rồi đây, giờ ghép code lại như sau:
function add_crawl_data(){
if (!is_admin() && isset($_GET['act']) && $_GET['act']=='crawl'){
//Code Crawler
$html_content = file_get_html('https://hoangan.net/wordpress');
if ( ! function_exists( 'post_exists' ) ) {
require_once( ABSPATH . 'wp-admin/includes/post.php' );
}
if (!empty($list_post)){
foreach ($list_post as $post){
$post_link = $post->find('.post_title h2 a', 0)->href;
$thumb = $post->find('.post_thumb img')->src;
//Post Detail
$html_detail = file_get_html($post_link);
$title = $html_detail->find('.content-entry .the_title h1', 0)->plaintext;
$content = $html_detail->find('.content-entry .the_content', 0)->innertext;
if (post_exists($title)===0){
$args = array(
'post_type' => 'post',
'post_status' => 'publish',
'post_title' => $title,
'post_content' => $content
);
$post_id = wp_insert_post($args);
if ($post_id>0){
wp_set_post_terms($post_id, 41, 'category');
Generate_Featured_Image($thumb, $post_id);
}
}
}
}
die();
}
}
add_action('init', 'add_crawl_data');
Cuối cùng, bạn thử chạy link crawl để xem kết quả. Thời gian chạy có thể hơi lâu do số lượng bài viết trong chuyên mục. Nếu bị timeout, bạn tải lại nhé.
Nếu bạn muốn lấy dữ liệu tự động, cứ có bài mới thì sẽ tự lấy về. Hãy đưa link chạy vào cronjob.
Nếu bạn muốn crawler các phân trang nữa thì bạn đưa đoạn code crawler đã làm ở trên vào một vòng lặp các trang.
Đến đây tôi nghĩ bạn tự làm được rồi.
Kết thúc
Trên đây, tôi đã hướng dẫn cơ bản cho các bạn cách thức Crawler Data trong WordPress sử dụng thư viện Simple HTML Dom
Nó không khó, nhưng đòi hỏi bạn phải có kiến thức về lập trình. Bài sau, tôi sẽ viết về chủ đề Crawler nội dung Render bằng Ajax.
Nếu có bất kỳ câu hỏi nào hãy comment dưới bài viết này.
Nguồn : https://hoangan.net